Custom scraper for your source — marketplace, API, registry. Stable runs, anti-bot bypass, delivery in the format you need.
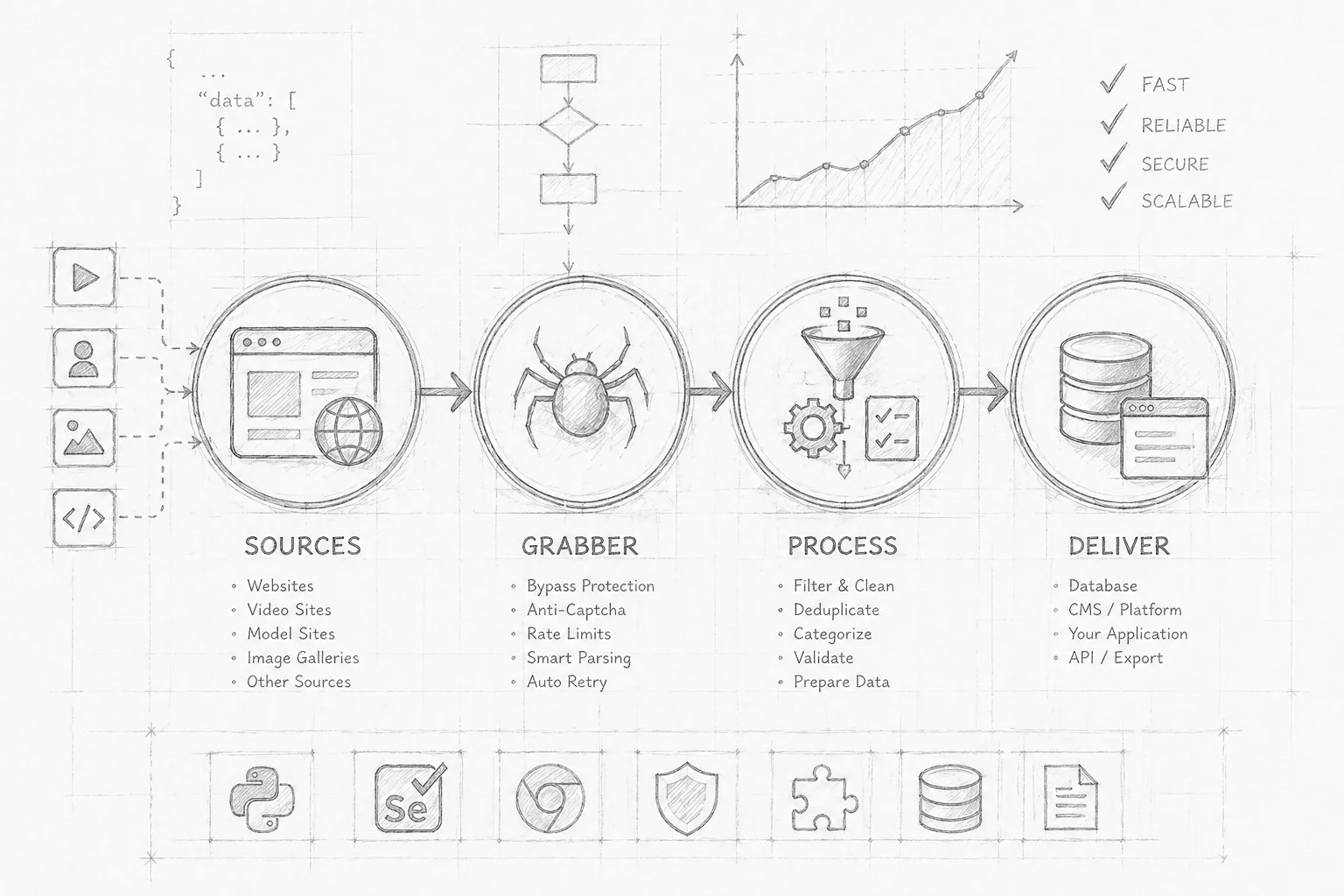
We build custom scrapers and data grabbers for automated collection from sites. Not just a one-off script — a real tool with processing logic, configuration, and runtime control. A fit for video, images, model data, categories, descriptions, and any other content type. The scraper can be implemented as a CMS module (KVS, WordPress, and others) or as a standalone service with its own admin and interface. The solution is shaped around the specific source and goals, including anti-bot bypass and automation of more complex collection scenarios.
Scraper development for a specific site or group of sites, with the data structure in mind.
Support for different content types: video (including HLS/m3u8), images, albums, models, categories, tags, and descriptions.
Implemented as a CMS plugin (KVS, WordPress, DLE, and others) or as a standalone service on your server.
Collection, filtering, and storage logic configured to deliver data in the format you need.
Authenticated runs (login/password) and access to gated content where needed.
Base anti-bot handling: Cloudflare, anti-captcha, access restrictions.
Automation tooling (Python, Selenium, etc.) to mimic real user behavior when needed.
Testing and tuning for stable long-running operation.
Base support after hand-off (fixes when the source structure changes).
Duplicate-protection so content is never collected twice.
Run logging for error tracking and process control.
Base control panel or settings for flexible configuration (runs, filters, collection parameters).
Data processing and normalization before storage (cleanup, structure, formatting).
The scraper is built as a managed system, not a one-off script. That means you can control the collection process, avoid duplicates, track errors, and scale the solution as the project grows.
The end result is a tool for automated data collection that lets you fill the site with content quickly or feed data into further processing and automation.
